Perfect Blue CTF 2021 BTLE Writeup
Misc - BTLE
I stored my flag inside a remote database, but when I tried to read it back it had been redacted! Can you recover what I wrote?
Flag Format: pbctf{flag+here} Author: UnblvR
For this challenge, we are given a .pcap file and must find a flag hidden within the Bluetooth traffic. To start off, I began by taking a look at the packets in the capture.
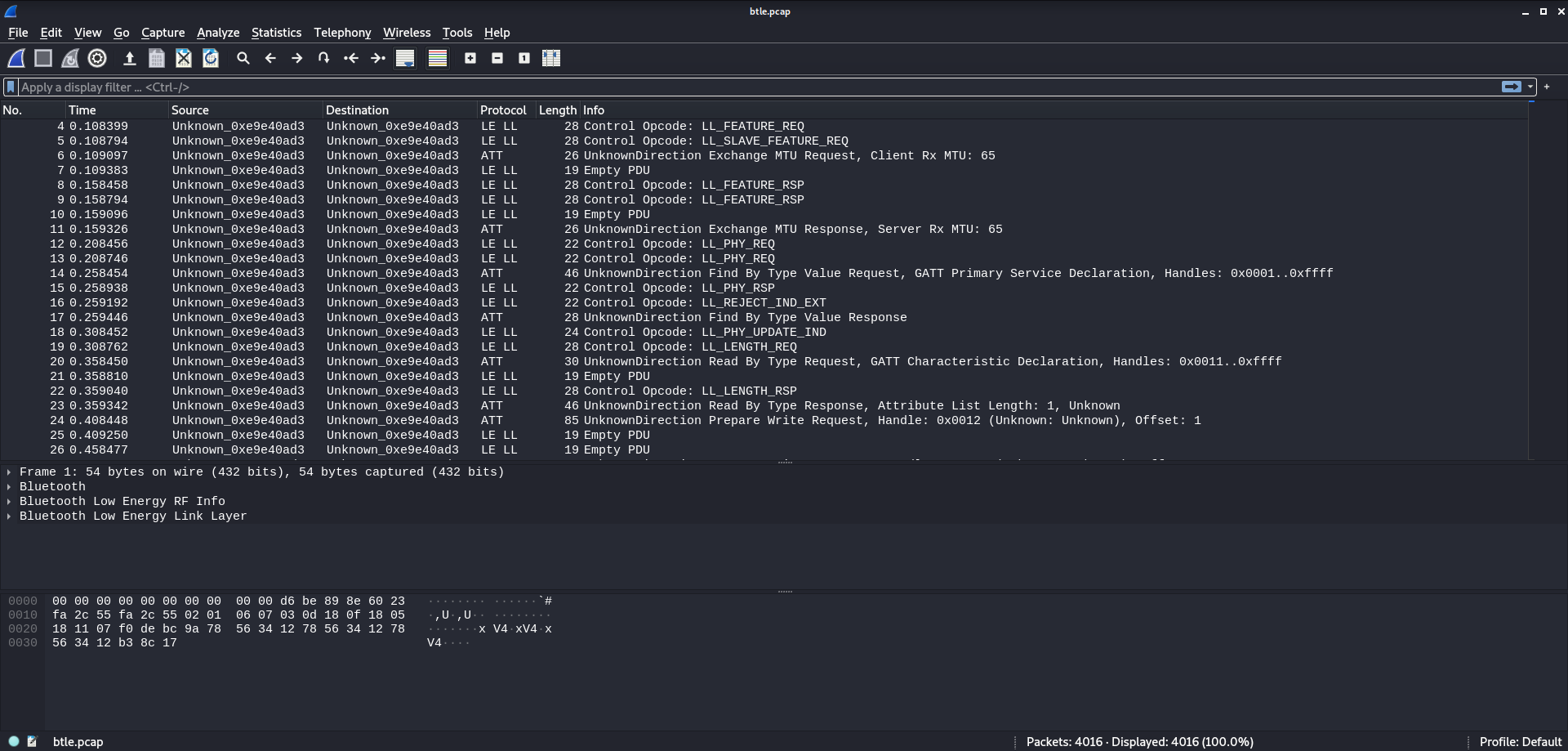
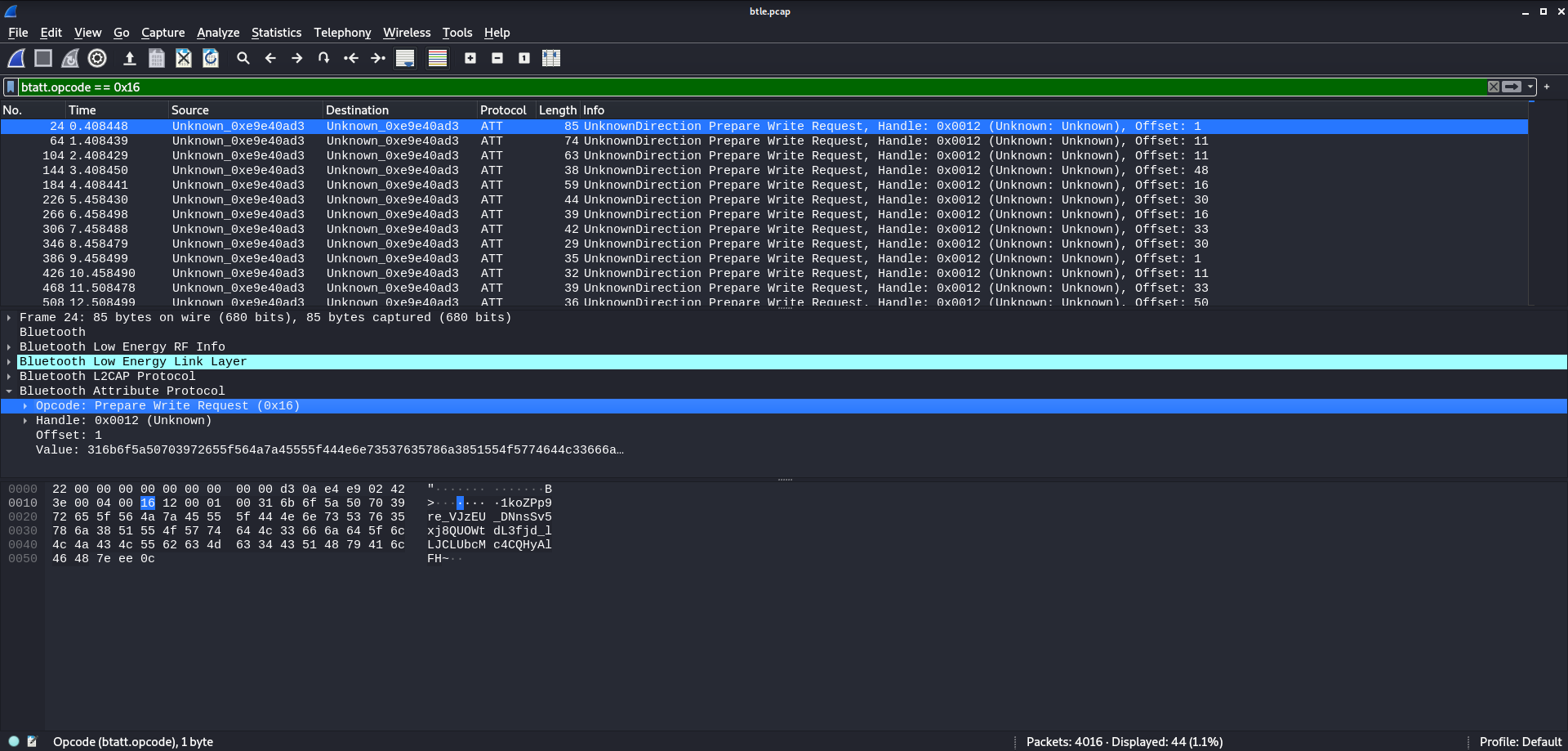
As Figure 1 shows, there are a couple of protocols at work here, LL LE and ATT. Both protocols belong to Bluetooth Low Energy communications. Judging by an initial glance at the capture, LL LE seems to handle all the connection details, while, ATT handles the data transferring processes.
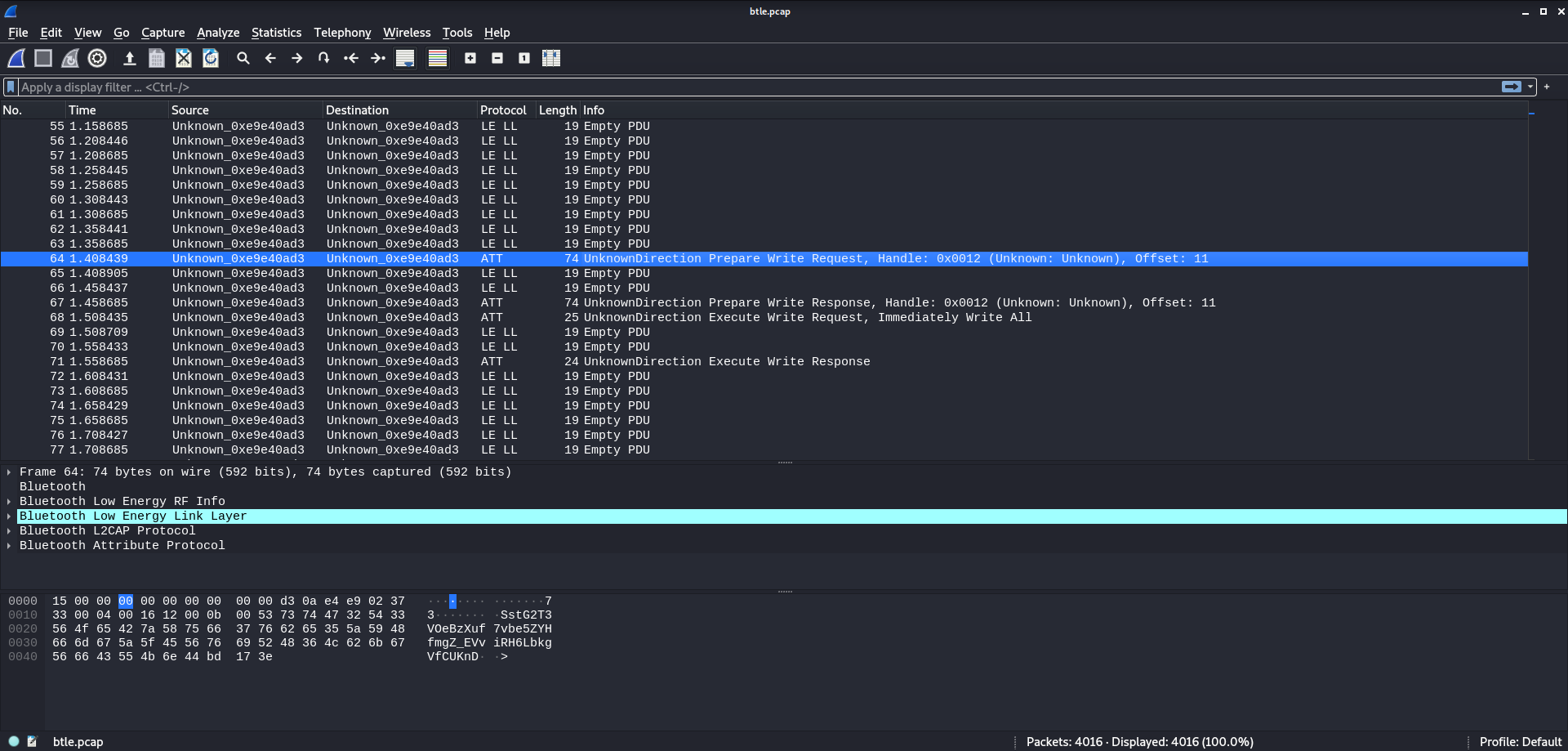
After the initial Bluetooth handshakes, the frames begin to alternate between a long sequence of “Empty PDU”s and a single “Prepare Write Request”. The “Empty PDU” frames serve only as a “keep-alive” mechanic for the Bluetooth connection. So filtering these frames out helps clean up the capture.
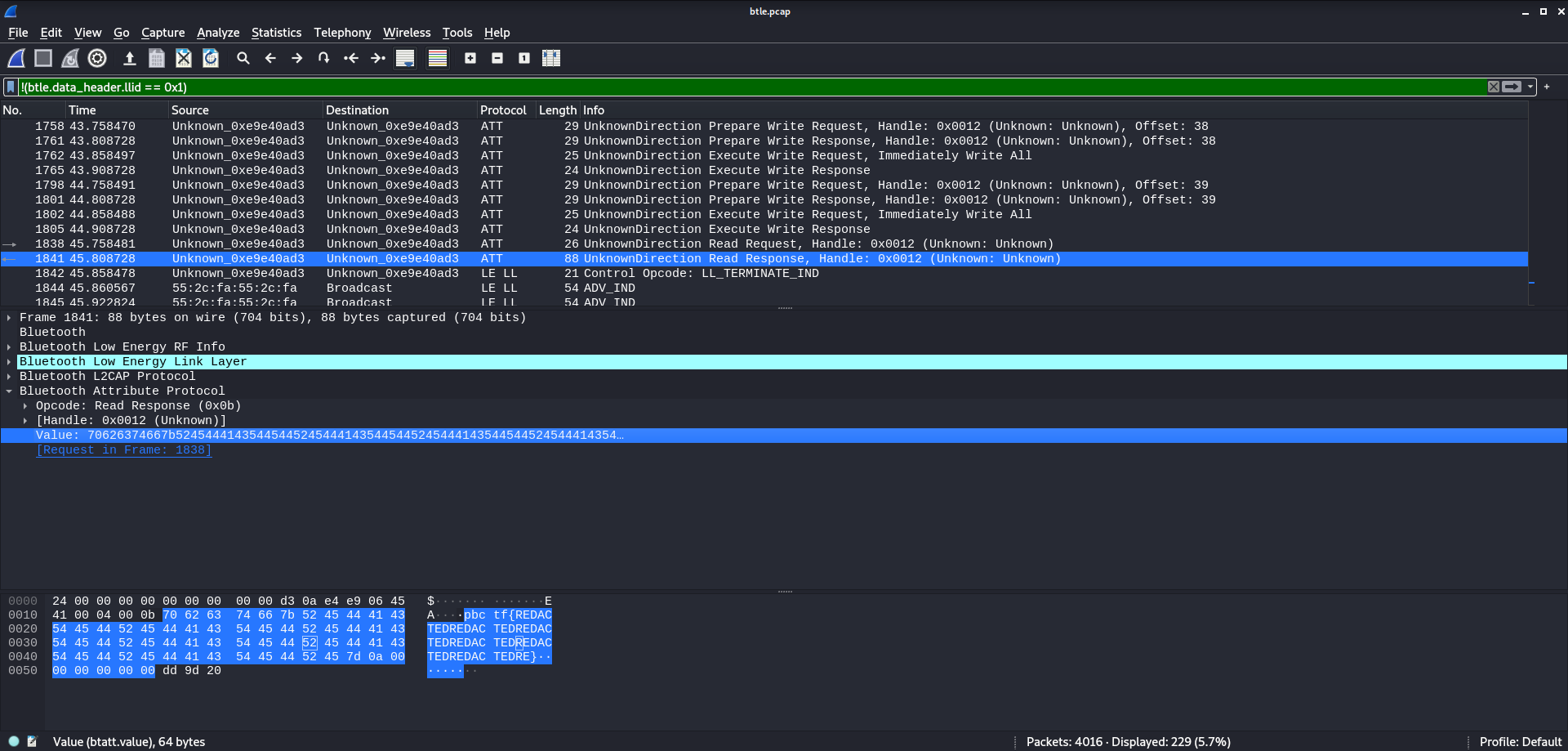
Near the bottom of the capture, there is a single read request which reveals exactly what the description noted, the flag has been redacted. Reading the flag directly doesn’t seem to be an option. However, the description also alluded to storing the flag at some point. So it seems reasonable that the write requests might hold the secret to revealing the flag.
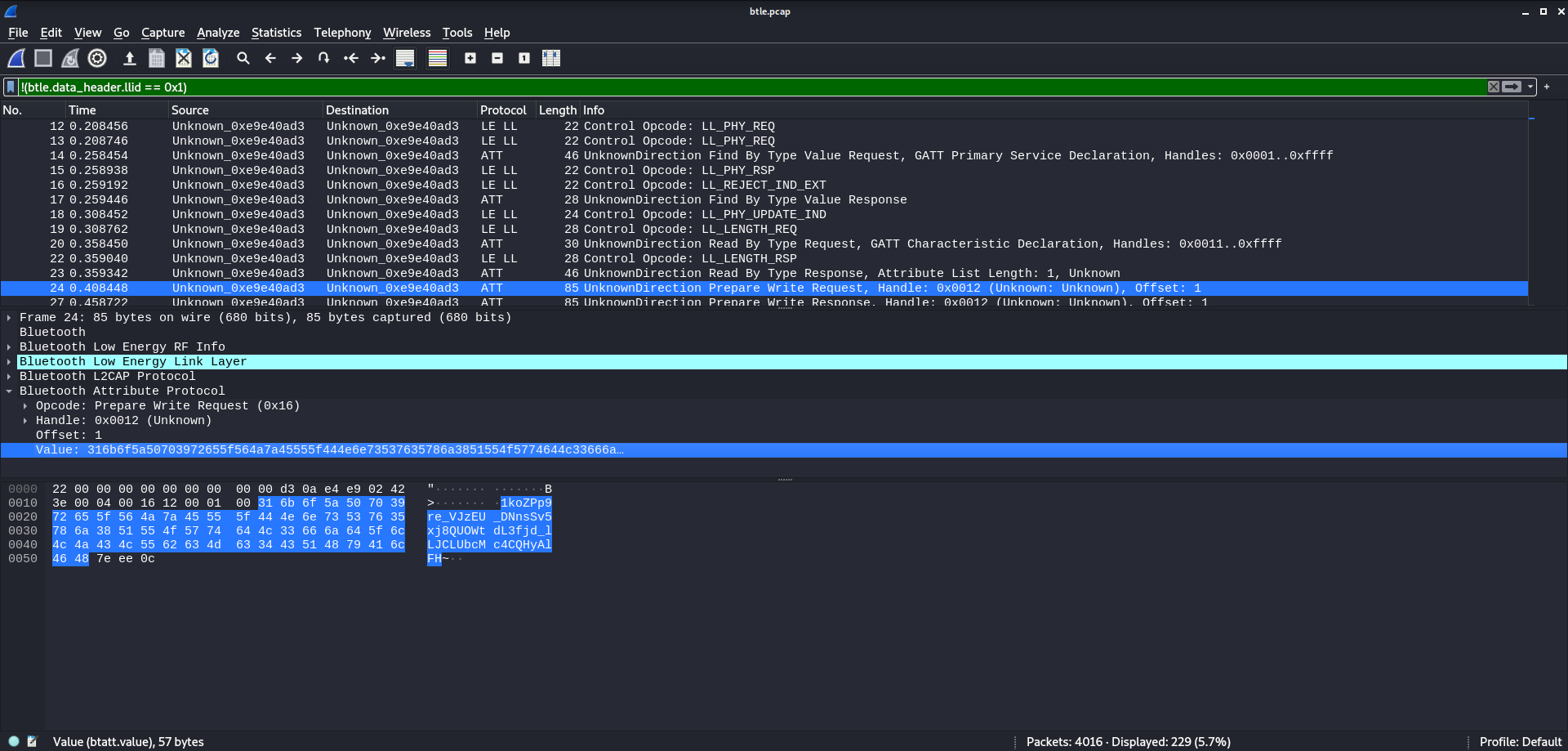
Each write request holds some text data, but they seem to just be strings of gibberish. Other than
the text, each write also has an offset value. After looking into the ATT protocol,
I learned that each write request will ask to write its data starting at this offset value.
This means that it is possible that the data from one write request will be overwritten by
another request. For example,
Request #1: Write abcdefg starting at OFfset 1
Database After Request #1: abcdefg
Request #2: Write xyz starting at Offset 2
Database After Request #2: axyzefg
With any luck, we can recreate the flag by performing all the write requests in order. To test this theory I performed a handful of requests by hand.
1koZPp9re_VJzEU_DNnsSv5xj8QUOWtdL3fjd_lLJCLUbcMc4CQHyAlFH
pcTNrWo
----------------------------------------------------------
pcTNrWore_VJzEU_DNnsSv5xj8QUOWtdL3fjd_lLJCLUbcMc4CQHyAlFH
t1zUgV
----------------------------------------------------------
pct1zUgVe_VJzEU_DNnsSv5xj8QUOWtdL3fjd_lLJCLUbcMc4CQHyAlFH
f{jtE
----------------------------------------------------------
pctf{jtEe_VJzEU_DNnsSv5xj8QUOWtdL3fjd_lLJCLUbcMc4CQHyAlFH
I did cheat a bit by ordering the writes by offset, but the test still confirmed the theory. Within a few steps, the flag was starting to reveal itself. As a follow-up, I filtered the capture in Wireshark to display only the “Prepare Write Request” frames.
Next, to simplify things, I exported these specific frames to a new .pcap using “File -> Export Specified Packets”. This makes creating a solver script easier since we don’t have to consider any unnecessary frames. Finally, here is the small Python script to mimic the write requests and extract the flag.
import re
def get_data(filename):
# Get data from capture
data = ""
with open(filename, 'rb') as f:
data = f.read()
# Add a segment on to the end so we don't miss a single character
data += b'\x00\xd5'
# Separate ble frames from each other
key_frames = re.findall(b'\x26\x60.+?(?=[\xd6|\xd5|])', data, re.DOTALL)
result = [""] * 100
# For each ble frame: trim unnecessary data and put it in the list at the correct offset
for frame in key_frames:
offset = frame[37]
text = list(frame[39:-4].decode())
result[offset:offset+len(text)] = text
print("".join(result))
return result
flag_parts = get_data("onlywrites.pcap")
print("".join(flag_parts))
The script follows this process:
- Get data from the new .pcap file
- Use regular expressions to find each individual frame
- Snip unnecessary bytes from the frames, leaving only the offset and text data
- Insert characters from the text data into a list starting at an index specified by the offset
A bit of investigating was required to figure out how Wireshark formats and separates each PDU in the .pcap hex. But once the specific byte sequence was found, it was a fairly smooth process from there.
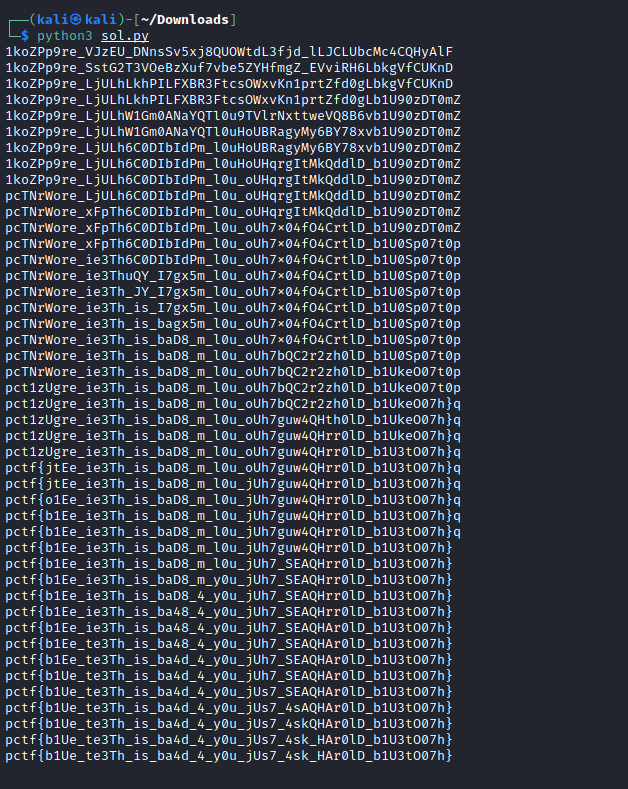
Figure 6 shows the results of the script. Some extra output was added to show the writing and overwriting process in action. For some reason the flag format is missing a “b” that I couldn’t even find inside the capture. Nonetheless, with a minor adjustment to the flag, the challenge is solved.
pbctf{b1Ue_te3Th_is_ba4d_4_y0u_jUs7_4sk_HAr0lD_b1U3tO07h}